
当机器学习遇上运动鞋
How GOAT Taught a Machine to Love Sneakers 当机器学习遇上运动鞋 How GOAT Taught a Machine to Love SneakersMissionAt GOAT, we’ve created the largest marketplace for buyers and sellers to safely exchange sneakers. Helping people express their individual style and navigate the sneaker universe is a major motivator for GOAT’s data team. The data team builds tools and services, leveraging data science and machine learning, to reduce friction in this community whenever and wherever possible.When I joined GOAT, I was not a sneakerhead. Every day while learning about new sneakers, I gravitated towards the visual characteristics that made each one unique. I started to wonder about the naturally different ways people new to this culture would enter the space. I came away feeling that, regardless of your sneaker IQ, we can all communicate about their visual appeal. Inspired by my experience, I decided to build a tool with the hope that others would find it helpful. 任务在 GOAT,我们为买家和卖家创造了一个最大的运动鞋安全交易市场。帮助

| How GOAT Taught a Machine to Love Sneakers | 当机器学习遇上运动鞋 |
How GOAT Taught a Machine to Love Sneakers
MissionAt GOAT, we’ve created the largest marketplace for buyers and sellers to safely exchange sneakers. Helping people express their individual style and navigate the sneaker universe is a major motivator for GOAT’s data team. The data team builds tools and services, leveraging data science and machine learning, to reduce friction in this community whenever and wherever possible. When I joined GOAT, I was not a sneakerhead. Every day while learning about new sneakers, I gravitated towards the visual characteristics that made each one unique. I started to wonder about the naturally different ways people new to this culture would enter the space. I came away feeling that, regardless of your sneaker IQ, we can all communicate about their visual appeal. Inspired by my experience, I decided to build a tool with the hope that others would find it helpful. |
任务 在 GOAT,我们为买家和卖家创造了一个最大的运动鞋安全交易市场。帮助人们表达他们个人的风格和定位的运动鞋世界是 GOAT 的数据团队的主要动力。数据团队构建一系列工具和服务,利用数据科学和机器学习,尽可能减少该社区可能出现的问题。 当我加入 GOAT 时,我并不是一个运动鞋狂热爱好者。 每天在处理新款运动鞋的同时,我更倾向于使每一个都有独一无二的视觉特征。 我开始疑惑那些刚接触这种文化的人会以何种方式进入这个领域。 我觉得,无论你对于运动鞋的审美水平如何,我们都可以传达他们的视觉吸引力。 受我的经验启发,我决定构建一个工具,希望其他人会觉得它有用。 |
|
The first place to start is developing a common language to describe all sneakers. However, this is not a simple task. With over 30,000 sneakers (and growing) in our product catalogue of unique styles, silhouettes, materials, colors, etc. attributing the entire catalogue manually becomes intractable. In addition, every shoe release creates the possibility of changing how we talk about sneakers, meaning we have to update the common language. Instead of trying to fight this reality, we need to embrace the variation and innovation by including them in our language from the beginning. One way to address this is to use machine learning. To keep up with the changing sneaker landscape, we use models that find relationships among objects without explicitly stating what to look for. In practice, these models tend to learn features similar to humans. I detail in this post how we use this technology to build visual attributes as the base of our common sneaker language. Latent Variable ModelsAt GOAT, we use artificial neural networks to approximate the most-telling visual features from our product catalogue i.e. latent factors of variation. In machine learning, this falls under the umbrella of manifold learning. The assumption behind manifold learning is that often the data distribution, e.g. images of sneakers, can be expressed in a lower dimensional representation locally resembling a euclidean space all the while preserving a majority of the useful information. The result is transforming millions of image pixels into interpretable nuanced characteristics encapsulated as a list of a few numbers. Manifold WHAT?Think about how you would tell your friend the directions to your home. You would never describe how to get from their house to yours in a series of raw GPS coordinates. GPS, in this metaphor, represents a high dimensional, wide-domain random variable. Instead, you would more than likely use an approximation of those coordinates in the form of a series of street names and turn directions, i.e. our manifold, to encode their drive. |
首先要开发一种用于描述所有运动鞋的通用语言。但是,这不是一项简单的任务。我们的产品目录中有超过 30,000 款运动鞋(并且数量正在增长),其中每款鞋独特的样式、轮廓、材料、颜色等都包含于整个目录,变得棘手。此外,每一款鞋子的版本都有可能改变我们谈论运动鞋的方式,这意味着我们必须更新它们的通用语言。因此我们需要通过从一开始就将它们包含在我们的语言中来接受变化和创新,而不是试图与现实作斗争。 解决方法之一是使用机器学习。为了跟上不断变化的运动鞋外观,我们使用可以找到对象之间关系的模型,而无需明确说明要查找的内容。在实践中,这些模型倾向于学习与人类相似的特征。我将在这篇文章中详细介绍我们如何使用这种技术构建视觉属性作为我们常见运动鞋语言的基础。
潜在变量模型 在 GOAT,我们使用人工神经网络来近似我们的产品目录中最具说服力的视觉特征,即潜在的变异因素。在机器学习中,这属于流形学习的范畴。流形学习背后的假设通常是数据分布,例如
运动鞋的图像可以在局部类似于欧几里德空间的较低维度表示中表达,同时保留大部分有用信息。结果是将数百万个图像像素转换为可解释的细微差别特征,并将其封装为少量数字的列表。 流形是什么? 想想你如何告诉你的朋友你家的路线。你永远不会描述如何通过一系列原始 GPS 坐标从他们的房子到你的房子。在这个比喻中,GPS 表示高维,宽域随机变量。相反,你很可能会以一系列街道名称的形式来使用这些坐标的近似值,并加上转向方向,即我们的流形,来编码它们的驱动器。
|
ModelingWe leverage unsupervised models such as Variational Autoencoders (VAE) [1], Generative Adversarial Networks (GAN) [7], and various hybrids [4] to learn this manifold without expensive ground truth labels. These models provide us a way to transform our primary sneaker photos into aesthetical latent factors, also referred to as embeddings. In many cases these models leverage the autoencoder framework in some shape or form for their inference over the latent space. The model’s encoder decomposes an image into its latent vector then rebuilds the image through the model’s decoder. Following this process, we then measure the model’s ability to reconstruct the input and calculate the incorrectness, i.e. loss. The model iteratively compresses and decompresses many more images using the loss value as a signal of where to improve. The reconstruction task pushes this “bowtie looking” model to learn embeddings which are the most helpful to the task. Similar to other dimensionality reduction techniques such as PCA, this technique often results in encoding the variability in the dataset.
Prototypic Autoencoder Gotchas and Design ChoicesSimply being able to reconstruct an image is often not enough. Traditional autoencoders end up being fancy look up tables of a dataset [1] with minimal generalization capabilities. This is a result of a poorly learned manifold with “chasms”/”cliffs” in the space between samples. Modern models are solving this problem in a variety of ways. Some, such as the famous VAE [1], add a divergence regularization term to the loss function in order to constrain the latent space to some theoretical backing. More specifically, most of these kinds of models penalize latent spaces that do not match some Gaussian or uniform prior and attempt to approximate the differences through a choice of divergence metrics. In a lot of cases, choosing the appropriate model comes down to the design choices of divergence measurement, reconstruction error function, and imposed priors. Such examples for design choices are the β-VAE[2, 3] and Wasserstein Autoencoder [4] which leverage the Kullback-Leibler divergence and adversarial loss respectively. Depending on your use case for learned embeddings you may favor one over the other as there is commonly a tradeoff between output quality and diversity. | 建立模型我们利用无监督模型,如变分自动编码器(VAE)[1],生成性对抗网络(GAN)[7] 和 Wasserstein 自动编码器(WAE)[4] 来学习这种流形,且无需代价高昂的实体标签。这些模型为我们提供了一种方法,可以将我们的主要运动鞋照片转换为美学上的潜在因素,也可称之为嵌入。在许多情况下,这些模型利用某种形式的自动编码器框架来推断潜在空间。模型的编码器将图像分解为其潜在向量,然后通过模型的解码器重建图像。在此过程后,我们测试模型重建输入的能力并计算其不正确性,即损失。该模型使用损失值迭代地压缩和解压缩更多图像,作为提高精度的信号。重建任务即为推动这个「bowtie looking」模型来学习对任务最有帮助的嵌入。与其他降维技术(如 PCA )类似,此技术通常会导致对数据集中的可变性部分进行编码。  原型自动编码器 陷阱和设计的选择仅仅能够重建图像通常是不够的。传统的自动编码器最终成为具有最小泛化能力的数据集 [1] 的奇特查找表。这是由于在样本之间的空间中具有「chasms」/」cliffs」的学习不佳的流形的结果。现在的模型正以各种方式解决这个问题。例如著名的 VAE [1],为损失函数添加了一个发散正则化项,以便将潜在空间约束到一些理论上的支持。更具体地说,这些类型的模型中的大多数惩罚与一些高斯或均匀先验不匹配的潜在空间,并试图通过选择发散度量来近似差异。在很多情况下,选择合适的模型可归结为发散测量,重建误差函数和强加先验的设计选择。设计选择的这些例子是β-VAE [2,3] 和 Wasserstein 自动编码器 [4],它们分别利用了 Kullback-Leibler 发散和对抗性损失。根据您学习嵌入的用例,您可能会偏爱另一个,因为通常需要在输出质量和多样性之间进行权衡。 |
| β-VAE Loss Function, reconstruction and weighted divergence terms In the case of aesthetic sneaker embeddings for our visual sneaker language, we prefer latent factors that encourage a robust and diverse latent space to cover a majority of our product catalogue. In other words we want to be able to represent the widest range of sneakers at the cost of not being so great with the really unique styles like the JS Wings. “Looks Like” Case StudyWe trained a VAE to learn a latent space of our primary product photos. Keeping the latent vector fixed, we can see how the model trains over time, building up layers of complexity and abstraction in a very human-like way.
Generated Photos through Decoder, each image is a fixed latent vector at progressively increasing epochs of training This model tends to create more independent human-interpretable factors per dimension [1, 2, 3] referred to as disentanglement. First, the model focuses on recreating the most appropriate silhouette with attention to the contrast between the sole and upper. From there, it constructs the notion of grayscale gradients across the silhouette until it starts to learn basic colors. After understanding silhouette types, e.g. boot vs. athletic, high vs. low the network begins to tackle the more complex design patterns and colors, which will be the final differentiators. To showcase the learned manifold and inspect the “smoothness” of the learned surface, we can visualize it further through interpolations [6]. We choose two seemingly different sneakers as anchors, then judge the transitions between them in latent space. Each latent vector along the interpolation is decoded back into image space for visual inspection and matched with its closest real product in our entire catalogue. The animation illustrates both these concepts to map the learned representation.
Interpolations and Matches between Anchor Sneakers Exploring the latent space further, we use a single sneaker and modify one factor at a time in every direction to observe how it changes. Factors representing “mid” to “boot”-ness and sole color are just a few visually perceivable characteristics learned by the network. Depending on the model the number of latent factors and their independence from each other varies. This disentanglement property is an active area of research for us, we hope will improve our embeddings. | β-VAE 损失函数,重建和加权发散项 对于我们的视觉运动鞋语言的美学运动鞋嵌入,我们更喜欢潜在因素,鼓励强大和多样化的潜在空间覆盖我们的大部分产品目录。换句话说,我们希望能够代表最广泛的运动鞋,而不是像 JS Wings 那样独特的风格。 「为什么看起来很像」的案例研究我们训练了一个 VAE 来学习我们的主要产品照片的潜在空间。保持潜在矢量处于固定状态,我们可以看到模型是如何随着时间的推移进行训练,以类似人类的方式构建复杂性和抽象层。
通过解码器生成的照片,每个图像都是一个在训练时期逐渐增加的固定潜在向量 该模型倾向于在每个维度 [1,2,3] 中创建更多独立的人类可解释因子,称为解构。首先,该模型着重于重新创建最合适的轮廓,同时注意鞋底和鞋面之间的对比。从那里开始,它构建了整个轮廓的灰度渐变概念,直到它开始学习基本颜色。在了解轮廓类型后,例如启动与运动,高与低后,网络开始解决更复杂的设计模式和颜色,这将是最终的差异化因素。 为了展示学习过的流形并检查学习曲面的「平滑度」,我们可以通过插值进一步可视化 [6]。我们选择两个看似不同的运动鞋作为锚点,然后在潜在的空间中判断它们之间的过渡。沿插值的每个潜在向量被解码回图像空间以进行视觉上的检查,并与我们整个目录中最接近的实际产品相匹配。下面的动画说明了这些概念以映射模型怎样学习。
锚点运动鞋之间的插值和匹配
进一步探索潜在空间,我们使用单个运动鞋,并在每个方向一次修改一个因素,以观察它是如何变化的。表示「中间」到「引导」的因素和唯一的颜色只是网络学习的一些视觉上可感知的特征。根据模型,潜在因素的数量和它们彼此的独立性会有所不同。这种解构属性是我们研究的一个活跃领域,我们希望能够改进我们的嵌入。 |
|
Latent Factors Exploration, varying one factors at a time per row with the same anchor sneaker, each column is the reconstructed latent vector at the amount of modification, prior is a standard normal distribution Furthermore, we can look at our entire product catalogue in terms of latent vectors in a dimensionally reduced 2D/3D plot to look for macro trends. We use tools such as t-SNE[5] to map our latent space into visualizations for spot checking and mass annotations.
t-SNE Latent Space Exploration Logically, if each sneaker is nothing but an aggregation of latent factors, then adding or subtracting these factors relative to each other becomes possible. Here is an example of adding two sneakers together. Notice how the results maintains the wide ankle loop and branding from the first sneaker while the sole, overall silhouette, and material can be attributed to the second.
Sneaker Image Latent Space Arithmetic TakeawaysEmbeddings are a fantastic tool to create reusable value with inherent properties similar to how humans interpret objects. They can remove the need for constant catalogue upkeep and attribution over changing variables, and lend themselves to a wide variety of applications. By leveraging embeddings, one can find clusters to execute bulk-annotations, calculate nearest neighbors for recommendations and search, perform missing data imputation, and reuse networks for warm starting other machine learning problems. |
潜在因素的探索,每一行使用相同的目标运动鞋改变一个因素,每列是修改量的重建潜在向量,先前是标准正态分布。 此外,我们可以在尺寸缩小的 2D / 3D 图中查看潜在向量的整个产品目录,以找到它们的宏观趋势。我们使用诸如 t-SNE [5] 之类的工具将我们的潜在空间映射到用于检查和批量注释的可视化界面。
t-SNE 潜在空间探索 从逻辑上讲,如果每个运动鞋只是潜在因素的集合,则可以相对于彼此相加或相减这些因子。这是一个将两个运动鞋加在一起的例子。注意结果是如何保持第一个运动鞋的宽踝环和品牌标识,且唯一的整体轮廓和材料属于第二个。
运动鞋潜在空间算法 小贴士
嵌入是创建可重用价值的绝佳工具,其固有属性类似于人类解释对象的方式。它们可以消除对变化变量的持续目录维护和归因的需要,并且适用于各种各样的应用程序。通过利用嵌入,可以找到群集来执行批量注释,计算推荐和搜索的最近邻居,执行缺失的数据插补,以及重用网络以热启动其他机器学习问题。 |
| GOAT’s Data Science & Engineering team is hiring! | GOAT 的数据科学与工程团队正在招聘! |
References | 参考文献 |


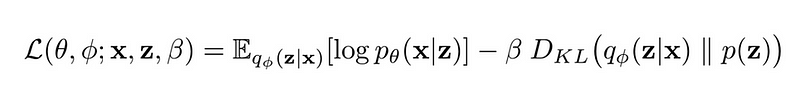




What's Your Reaction?
















