
银行业中的数据挖掘-贷款审批案例
Data mining for Banking: Loan approval use case 银行业中的数据挖掘-贷款审批案例 Data mining for Banking: Loan approval use caseBanks fundamental business model rely on financial intermediation by raising finance and lending (mortgage, real estate, consumer and companies loans). the latter is the major source of credit risk composed from 2 main points loan approval and fraud. in this post we will focus on loan approval by using data mining models.Granting credit to both retail and corporate customers based on credit scoring is key risk assessment tool that allow optimally managing, understanding and quantifying a potential obligor’s credit risk through “creditworthiness score”, which represent a more robust and consistent evaluation technique comparing to judgmental scoring.Credit scoring in retail portfolios reflects the default risk of a customer at the moment of loan application, it helps to decide whether to accept or reject credit application based on 4 main input data:· Customer information:
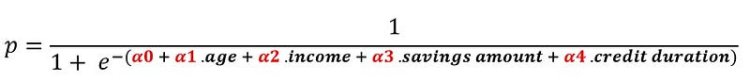
| Data mining for Banking: Loan approval use case | 银行业中的数据挖掘-贷款审批案例 |
Data mining for Banking: Loan approval use caseBanks fundamental business model rely on financial intermediation by raising finance and lending (mortgage, real estate, consumer and companies loans). the latter is the major source of credit risk composed from 2 main points loan approval and fraud. in this post we will focus on loan approval by using data mining models. Granting credit to both retail and corporate customers based on credit scoring is key risk assessment tool that allow optimally managing, understanding and quantifying a potential obligor’s credit risk through “creditworthiness score”, which represent a more robust and consistent evaluation technique comparing to judgmental scoring. Credit scoring in retail portfolios reflects the default risk of a customer at the moment of loan application, it helps to decide whether to accept or reject credit application based on 4 main input data: · Customer information: age, gender, marital status, job, incomes/salary, housing (rent, own, for free), geographical (urban/rural), residential status, existing client (Y/N), number of years as client, total debt, account balance. · Credit information: Total amount, purpose, amount of the monthly payment, interest rate, … · Credit history: Payment history and delinquencies (payment delays), Amount of current debt, number of months in payment arrears, Length of credit history, time since last credit, Types of credit in use. · Bank account behavioral: average monthly savings amount, maximum and minimum levels of balance, credit turnover, trend in payments, trend in balance, number of missed payments, times exceeded credit limit, times changed home address | 本文相关概念: 1、银行数据挖掘:贷款审批用例银行的基本商业模式是作为金融中介----通过筹集融资和贷款(抵押贷款,房地产,消费者和公司贷款)。后者是2个主要贷款审批和欺诈组成的主要信用风险来源。在这篇文章中,我们将通过使用数据挖掘模型来关注贷款审批。 基于信用评分向零售和企业客户授予信用是关键风险评估工具,其允许通过“信誉评分”来最佳的管理、理解和量化潜在的债务人的信用风险,相对和“评判评分”相比,“基于信用评分”是更稳健和一致的评估技术。 零售投资组合中的信用评分反映了贷款申请时客户的违约风险,它有助于根据4个主要输入数据决定是接受还是拒绝信用申请: ·客户信息:年龄,性别,婚姻状况,工作,收入/工资,住房(租金,自有,免费),地理(城市/农村),住宅状况,现有客户(Y / N),客户年数,总债务,账户余额。 ·信用信息:总金额,用途,月付金额,利率,...... ·信用记录:付款记录和拖欠(付款延迟),当前债务金额,拖欠付款的月数,信用记录长度,自上次信用以来的时间,使用中的信用类型。 ·银行账户行为:平均每月储蓄金额,最高和最低余额水平,信用额度,支付趋势,余额趋势,未付款数量,超过信用额度的次数,更改家庭住址的次数 |
Feature Selection and ModelsData mining increases understanding by showing which factors most affect specific outcomes: Correlation matrix helps to dismiss correlated variable and feature selection methods (particularly Multivariate correlations) like stepwise regression are used to filter irrelevant predictors; it adds the best feature (or deletes the worst feature) at each round, and evaluate model error in each iteration using cross-validation to finally keep the best predictors subset (“feature selection” subject will be tackled in a separate post). Logistic regression and decision trees are both popular classification techniques (supervised learning) used to build behavioral scorecards, they are statistical methods that analyse a dataset to bring out the relationship between “predictors” (or explanatories) that are independent variables and a “response” (or Outcome variable) that is a dependent variable. In our case we try to estimate the probability of granting a loan given the value of input variable seen above. For simplification, we will restrict the number of variables to 4 following predictors “age, income, average monthly savings amount, credit duration”. Logistic RegressionIn logistic regression, the target y is binary (Granted p = 1 /Not granted p = 0) and the probability p of granting the credit. The goal is to find coefficients αi of the formula below to predict a logit transformation of P. Logit (p) = log(p/[p-1])= α0 + α1 . age + α2 . income + α3 . savings amount + α4 . credit duration | 2、特征选择和模型数据挖掘通过显示哪些特征(因素)对特定结果影响最大来增加理解:关联矩阵有助于消除相关变量,特征选择方法(特别是多元相关)如逐步回归用于过滤不相关的预测变量; 它在每一轮中添加最佳特征(或删除最差特征),并在每次迭代中使用交叉验证评估模型误差,以最终保持最佳预测器子集(“特征选择”主题将在单独的文章中处理)。 逻辑回归和决策树都是用于构建行为记分卡的流行分类技术(监督学习),它们是分析数据集的统计方法,分析独立变量的“预测者”(或解释者)和因变量的“响应”(或结果变量)之间的关系。在我们的例子中,我们试图根据上面给出的输入变量的值来估计给予贷款的概率。为简化起见,我们将变量数量限制在4个预测变量“年龄,收入,平均每月储蓄金额,信用期限”之后。 Logistic回归在逻辑回归中,目标y是二元的( 授予 p = 1 /不授予 p = 0) 和 授予信贷的概率p。目标是找到下面的公式的系数αi 来预测P的logit变换。 Logit(p)= log(p / [p-1])=α0+α1.年龄+α2 . 收入+α3 . 储蓄金额+α4 . 信用期限 |
|
To find coefficients αi we train the classification model with a labelled data history, where the decision “granted”/”not granted” is already known, by using Cross-entropy as loss function to compare the predictions ^y vs labels y :
The values of αi are those that minimize L(α0,.., α4) using its first derivative and an optimization algorithm like gradient descent: Decision Tree
In decision Tree (like CRT, QUAID, QUEST, C5.0) we build classification model that learn decision rules inferred from data features to make predictions, generating a tree structure with decision nodes corresponding to attributes (input variables). · Step 1: use splitting criterion (like Information Gain, Gain Ratio, Gini Index) to select the attribute with the best score that will be chosen to produce the purest node regarding to the target variable (in our case, the attribute that best separates “Granted” from “Not granted”). · Step 2: create the root split node with the consequents subsets, then repeat step 1 for each subset by reusing splitting criterion to select the next best attribute to produce the purest sub-nodes regarding to the target variable. · Step 3: repeat step 2 until reaching a stopping Criteria, for instance: Purity of the node > pre-specified limit or Depth of the node > pre-specified limit or simply Predictor values for all records are identical (no more rule could be generated) |
为了找到系数αi,我们用标记的历史数据训练分类模型,其中 已经知道“授予”/“未授予” 的决定,通过使用交叉熵作为损失函数来比较预测^ y vs标签y:
αi的值是使用其一阶导数和梯度下降等优化算法最小化 L(α0,...,α4)的值: 决策树 在决策树(如CRT,QUAID,QUEST,C5.0)中,我们构建分类模型,学习从数据特征推断出的决策规则以进行预测,生成具有与属性(输入变量)对应的决策节点的树结构。 步骤1:使用分割准则(如信息增益、增益比、基尼系数等)选择得分最高的属性,生成与目标变量相关的最纯粹节点(在我们的例子中,最佳区分“授予”和“未授予”的属性)。
|
| · Step 4: apply Pruning to avoid overfitting by using a criterion to remove sections of the tree that provide little power to classify and determine the optimum tree size. To do so, we create distinct dataset “training set” and “validation set”, to evaluate the effect of pruning and use statistical test ( like Chi-square for CHAID) to estimate whether pruning or expanding a given node produce an improvement. We have two types of Pruning: o Pre-pruning stop growing the tree earlier, before it perfectly classifies the training set. o Post-pruning allow the tree to grow and then prune it back. ConclusionLogistic regression is a popular for modeling scorecard that have a continuous range of scores between 0 and 1, contrary to decision trees which have only a limited set of score values (every leaf node = particular score), thus, it may not be sufficient to provide a fine distinction between obligors in terms of default risk. In addition, we can use other models like discriminant analysis, neural networks, and support vector machines (SVMs); or we can combine them by using ensemble methods such as bagging for more stability and boosting for more accuracy (ensemble methods will be addressed in a separate post). |
结论Logistic回归是一种流行的建模记分卡,其得分在0到1之间,与只有一组有限的得分值(每个叶节点=特定得分)的决策树相反,因此,它可能在区分债务人违约风险方面不够精细。 此外,我们可以使用其他模型,如判别分析,神经网络和支持向量机Logistic回归是一种流行的“建模记分”分类模型,其得分在0到1之间,与只有一组有限的得分值(每个叶节点=特定得分)的决策树相反,因此,它可能在区分债务人违约风险方面不够精细。 此外,我们可以使用其他模型,如判别分析,神经网络和支持向量机(SVM); 或者我们可以通过使用集成学习算法方法(如bagging )来组合它们以获得更高的稳定性和提升以获得更高的准确度(集成学习算法将在单独的文章中解决)。 |




What's Your Reaction?
















